Essay:
cc
Why 'Searching' Can’t Solve Business Complexity: Common Search vs. High Entropy
Every leader we have talked to is wrestling with the same paradox: we have more documented information than ever before, yet it is challenging to find clarity on what is actually happening in our companies.
We have spent the last decade deploying tools to capture everything. We have Slack for our conversations, Notion for our docs, Jira for our tasks, and meeting recorders for our calls. Theoretically, the answer to every question about the business in the past and present is "in there" somewhere. But in practice, trying to understand the status of a complex initiative feels like trying to assemble a puzzle where the pieces are scattered across a thousand different boxes.
We call this the Decision Context Problem.
Most of us assume this is a search problem. The logic goes: "If we just had a better search bar, or a better AI to search for us, we could find the right documents and get the answer." We treat our company data like a library, assuming that if we can just locate the right book, we’ll find the knowledge.
But for your most important work, like strategic goals, major product launches, or shifting market positions, the answer isn't in a single document. It is scattered across hundreds, or even thousands, of email threads, meeting transcripts, and comment sections. This is what we call "high entropy" context.
And here’s the inconvenient truth: standard search tools, even the ones powered by modern AI, are failing to solve the problem.
The Standard Playbook: The Limits of Common Search
To solve AI-assisted search, the industry has largely converged on a single type of architecture: Retrieval-Augmented Generation (RAG).
The RAG architecture can be applied directly to a database of information, or can query data from external sources. For example, the concept of RAG is effectively what powers customized intelligence in ChatGPT or Claude after you connect your personalized sources (think GitHub, Google Drive, etc). In these cases, the background process is more technically advanced, e.g. MCP protocols, but the underlying idea is very similar.

These common search methods are fancy ways of exploring your data to chat with it. When you ask a question the system searches your data for relevant snippets of text (retrieval), pastes them into a prompt, and asks an AI to write an answer based on those snippets (generation). It is the standard playbook because it is cost-effective and largely prevents the AI from making things up (hallucinating).
For "low entropy" tasks, this search-based approach is magic. If you ask "What is our remote work policy?" the system finds the single specific PDF that contains the answer, feeds it to the AI, and you get a perfect summary. The context is contained, stable, and easy to find.
The 'High Entropy' Trap
The problem is that the most critical business questions are rarely about static policies. They are about dynamic, messy realities.
Take a complex business goal like "Q3 mobile app launch". The data isn’t contained within a single document. Rather, context is spread across a network of 1,500 Slack messages, weekly meeting transcripts, and countless email threads. This type of information is called "high entropy" due to this sprawl and disorder of context.
When you point a standard search-based system at a high entropy topic, it hits two hard walls:
- Retrieval Limits: The search retrieval algorithm usually fetches up to a limit - something like "top 10" or "top 20" most relevant snippets. It inevitably leaves details behind.
- Context Windows: Even if you could retrieve all 1,500 documents, you can't feed them all into the AI at once. The AI's "context window" (its short-term memory) has a limit. You simply cannot reliably cram the entire history of an elaborate project into a single prompt. Sure, context windows have been increasing in size - up to millions of tokens - but there are still issues with attention mechanisms, i.e. the AI “remembering” everything perfectly across such a large body of text.
So the system is forced to guess. It retrieves a handful of fragments - maybe a Jira ticket from last week, an email from two months ago, a status update from a few days ago - and tries to stitch them into a coherent story. It gives you an answer that is technically "grounded" in data, but factually incomplete.
For complex business questions, common search methods don't just struggle, they hit technical limits. We suspected that at least part of the answer wasn't to search better, but to change the underlying data structure [1]. If the context is too complex to find via keyword search, we shouldn't be trying to retrieve it raw. Instead, we should be trying to compress the entropy of all of the relevant information.
The Experiment: Testing Search vs. Compression
To test this, we moved beyond theory and ran a controlled experiment using a dataset of real-world business communications including: email threads, meetings, tasks, and comment threads. We wanted to see if we could improve the AI’s ability to answer complex questions by changing how we presented the context to it.
The Architecture: Graphs and Communities
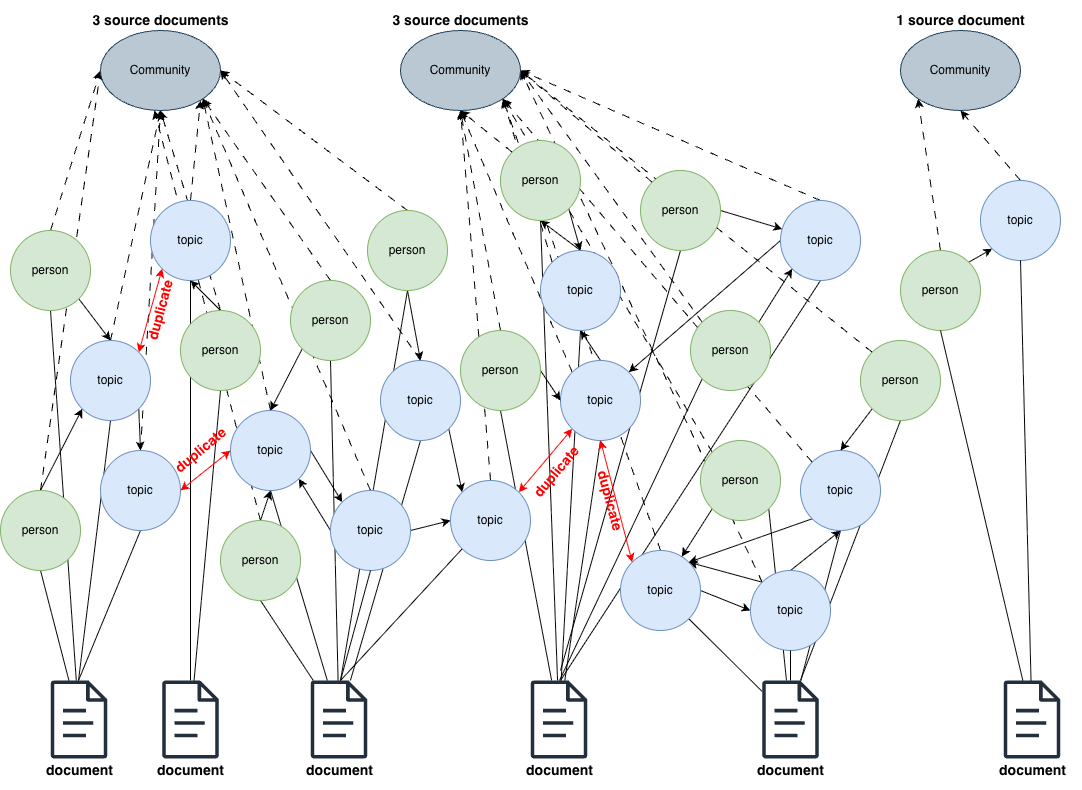
Before running any tests, we had to structure the data. Instead of treating our dataset as a flat list of files, we constructed a knowledge graph of “topics” and people. In this context, topics are purposely loosely defined as “A person or thing that is being discussed, described or acted upon. A person’s attention is scoped to a topic.” Topics define the scope of the concept, and they have the effect of drawing mental boundaries around things, which is useful because humans have limited attention. What we call “business context” is a collection of topics - at the highest level of business context “the business” is the top level topic, but it’s composed of many (infinite) sub topics.
A knowledge graph is like a giant, digital map that connects difference pieces of information to show how they are related to each other, much like a giant web of facts. Typically, we call the "things" in a knowledge graph "nodes" (e.g. the facts, topics, people, etc), and nodes are connected by "relationships". For example, instead of just listing two places separately, like Paris and France, a knowledge graph connects the two by a relationship to indicate that Paris is the capital of France.
We mapped over 14,000 nodes representing topics and people, drawing relationships between them based on interactions (e.g., who attended which meeting, which email mentioned which project, etc).
Next, we had to identify the high entropy topics. To do this we used an approach similar to hierarchical GraphRAG summarization [2]. Specifically, we applied the Leiden graph community detection algorithm to find the high-level communities (densely connected areas of the knowledge graph) of topics in the graph. This allowed us to mathematically identify specific clusters of topics (e.g. “Q3 Marketing Push”) based on relationships, rather than relying on semantic similarity between document content alone. Summaries of each community were distilled from the descriptions of the community member nodes and relationships.
Throughout this process we also kept track of the number of source documents associated with each community, and identified high entropy topics based on a lower threshold of the number of source documents from our previous research [1]. Simply put, topic communities that correspond to many source documents are the high entropy topics we are interested in - they sprawl across many pieces of individual information. Those high entropy topic communities were then indexed to be available for search.
With this graph structure in place, we tested two different approaches to make use of it.
The Intuitive Approach That Failed: Scoped Search
Our first hypothesis was one that most teams (including ours) naturally gravitate toward: Focus.
We assumed that if we restricted the AI’s content search during retrieval only to content associated with topic communities relevant to the question, the answers would get better. We called this "Scoped Search." The logic seemed reasonable: if you remove the noise of unrelated projects, the signal should become clearer.
It failed. In fact, scoped search performed worse than our blind baseline.
We processed 100s of user queries through the search system. Also, we divided the user queries into two distinct sets: those that were directly related to the high entropy topics and those that were related to low entropy information. This allowed us to gauge a comparison of performance between scenarios where we might expect topics communities to shine, and not be relevant at all.
For this particular experiment, we expected the scoped search to definitely fail for "low entropy" user queries, since none of the "high entropy" topics would get matched during search - any matches would be purely based on loose semantic similarities.
In contrast, the high entropy user queries were designed to match well with the high entropy topics, and so we expected better results due to that context alignment.
After the search results were retrieved we manually evaluated the relevancy between search content results and each query on a scale of 0-3. Content was considered relevant if the score was >= 2. We also evaluated the LLM-generated answers to the user queries.
Based on this scoring, performance metrics were evaluated:
- Mean reciprocal rank
- Recall@k
- Precision@k
- NDCG@10
These metrics measured how complete, accurate, and well-ranked the results were.
For most metrics we found statistically significant differences compared to the baseline search implementation. This means that for most metrics the results were clear enough to indicate that differences weren't just due to random luck or chance.
As expected, performance metrics for the "low entropy" user queries was very poor.
However, even for user queries directly related to topics communities, the approach showed statistically significant differences in performance between -7% and -13%, and the generated responses were materially worse (statistically speaking), compared to the baseline approach. There were no detectable positive differences observed for the scoped search approach across all metrics and evaluations.
On the surface, these results were quite surprising, at least to us. So, why do we observe these results?
When you think deeply, this approach actually exemplifies the “high entropy trap”. First, we have actually not stripped away the noise of irrelevant content, since a search result could potentially only relate to the community topic in a minor way and therefore the text within the content is still noisy. Second, even if only purely relevant content was returned we have the classic common search problem: the AI is not able to create a coherent story since it is still limited by how much content is retrieved and it can handle. This clearly highlights that you can’t just filter your way to a better answer for a high entropy question.
Our Solution: High Entropy Compression
What is needed is a way to make high entropy context easily digestible. We turned to information compression.
This approach simply treated the indexed topics communities like “regular” content in our business context data store during retrieval. The community summaries effectively represent a “cliff notes” version of the topic. Thus, when a user asks a question the AI isn’t forced to hunt through raw email threads; it could pick up these pre-computed and highly relevant summaries during retrieval to include when generating a response, just like a meeting transcript or Jira ticket would.
We ran this RAG approach over the same 100s of user queries we used for the scoped search analysis. The results yielded measurable differences in performance metrics compared to the baseline ranging from +7% to +20% when considering the sample of user queries directly related to the topics communities. No relevant differences were observed for the sample of low entropy user queries - so there was no noticeable difference when high entropy topics were not relevant to the query, which is expected.
We believe the reason for these increases in performance is simple: We bypassed the retrieval limits and context window constraints entirely. The AI wasn't searching for many needles in a haystack anymore; it was reading a clear and concise map to those needles. Furthermore, our results indicate that if a user query also contains low entropy information, the AI also gets those context gaps filled in with the standard search retrieval.
Conclusion: The Shift from Retrieval to Synthesis
Our research indicates a clear, if uncomfortable, conclusion for anyone building or buying business tools: You cannot solve business complexity by just building a better search bar.
Since the advent of AI-assisted search, the assumption has been that if we just index enough documents and make the retrieval fast enough the "Context Problem" will disappear - you will have almost instantaneous access to all of your relevant data! Our research suggests the opposite. As the entropy of your work increases - as your goals and work become more ambitious and your teams more interconnected - standard search techniques becomes less effective, not more, or even the same.
If we want tools that actually help us make decisions, we have to move from retrieval (finding data on the fly) to synthesis (understanding structure in advance) of complex information.
This is not a trivial shift. It requires a fundamental change in how we architect our systems:
- Moving beyond list structures: We have to stop storing information only in flat lists. We need to invest in infrastructure that maps the tangible, complex relationships between people, work, and other business information. In this research we used a graph approach to structure that information.
- From real-time to pre-computed: The most important business context has high entropy, and we should be compressing that information ahead of time to summarize the noise into a signal.
None of the popular search systems, like ChatGPT, Claude, or your favourite RAG pipeline, have the capability to do this as they exist now. And I think those systems' architectural limitations are the main reason why I often find myself thinking "well, it's not wrong... but... it's not quite right, either". I strongly think that information compression is a step in a more helpful direction, compared to blindly bolting more "features" and connections onto common AI-assisted search architectures.
References
Your message here
Thanks for getting in touch, I'll reply shortly!