The Power of Knowledge Bundles: Just-in-Time Compression for Better AI Deep Research
Answering a question about a complex initiative is rarely as simple as opening a single document. The reality is much messier. The complete picture is "high-entropy": information is scattered across thousands of Slack threads, meeting transcripts, and emails.
While Large Language Models (LLMs) and standard retrieval-augmented generation (RAG) pipelines attempt to solve this, they fundamentally struggle with high-entropy data - information spread across many sources of truth. When relevant context is this fragmented, standard RAG hits hard retrieval limits and easily maxes out AI context windows, failing to capture the full story.
In our previous research, our solution was to shift the burden: compress the entropy before a user ever asks about it. By using pre-computed summarization of knowledge graphs, we gave the AI a highly curated "cheat sheet" that significantly boosted RAG performance.
But this pre-compression came with important trade-offs. Generating and continuously synchronizing a knowledge graph requires considerable engineering effort. If the business moves faster than your graph updates, the context gets stale. Furthermore, because the data is summarized ahead of time, it is often not quite right for any given specific and nuanced question a user could ask.
This motivated us to explore dynamic alternatives that solve the high-entropy problem, but do not require the infrastructure of a pre-computed graph.
Just-in-Time Knowledge Bundles
A really interesting post from Dropbox sparked a new idea: What if we can achieve the benefits of knowledge graphs dynamically, at the exact moment a user asks a question, but without formally constructing a knowledge graph?
That is, instead of relying on a pre-computed map of the entire business, we could build "knowledge bundles" on-the-fly during query time.
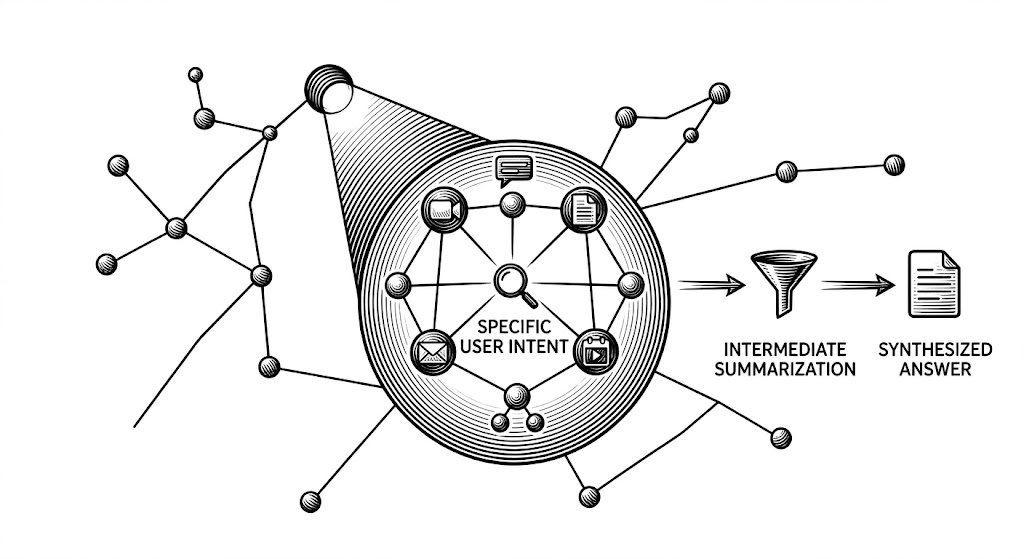
By pulling together focused knowledge bundles at the exact moment of the query, we could dynamically gather scattered pieces of high-entropy data on demand. Because it is compiled in real-time, the context is perfectly tailored to the user's specific intent. This theoretically handles high-entropy data by synthesizing only the necessary fragments right when they are needed, eliminating the need to maintain a persistent knowledge graph.
The expanded context is then either fed directly into an LLM's context window (giving the AI all the raw materials right before it answers) or compressed via summarization before generating the final output report (filtering out the noise so the AI only reads the highest-signal information).
Engineering the Experiment
To test this architecture in practice, we modified our RAG pipeline to dynamically enrich the prompt context before it reached the final report generation step. We built and tested several different pipeline variants to figure out the best way to build these knowledge bundles.
Our experimental strategies included:
- Author Context: Injecting information about the author of each RAG result, like name and organizational bio.
- Recent Author Activity: For each author of the retrieved results, pulling their most recent or topic-relevant activities to build an expanded timeline of their work.
- Semantic Similarity Expansion: For every initially retrieved document, running a secondary vector similarity search to pull in other documents that share the exact same concepts, even if they don't share the exact same keywords.
- Intermediate Summarization: Taking those secondary search results and compressing them into summaries based on the user's input query before passing them downstream. Think of this as an automated research assistant highlighting the most important points before handing the final stack of papers to the lead analyst.
- Combinations: Merging these techniques in various configurations to find the optimal balance.
To evaluate these variants, we put the outputs to a blind test with our team, running various high-entropy business queries and judging the reports on quality directly against our unmodified RAG pipeline.
The Winning Approach, with a Catch
In the team evaluations, a distinct preferred approach emerged, winning in 64% of the trials. The most successful variant combined semantic similarity expansion, intermediate summarization, and author context into a single, multi-step pipeline.
The deep research reports from this approach were thorough and successfully tied scattered communications back to overarching organizational goals. We believe it worked so well because it effectively built a highly relevant "local subgraph" of knowledge on-the-fly. Instead of querying a pre-built map of the whole company, the pipeline looked at the initial search results, radiated outward to find related context, compressed that specific neighborhood of information, and bundled it together into a temporary, custom-built map perfect for that one specific question.
Perhaps unsurprisingly, this approach came with important tradeoffs:
- Runtime latency: The pipeline was roughly 1.6x slower than our baseline RAG approach, largely because the summarization of the extra documents takes time.
- Token usage: Naturally, the intermediate summarization step used a large amount of tokens. For our specific deep research architecture, we saw a roughly 10x increase in token usage per research run.
When using a pre-computed graph, the latency and token cost are paid upfront during the build and update phases. In contrast, when fetching a local subgraph on-demand, that price is paid at query time, every single time. The benefit is perfect relevance for the given input question; the downside is that running this with large frontier models is prohibitively expensive.
Balancing Tradeoffs: Getting Large Model Performance from Small Models
We didn't want to abandon the dynamic approach, so we set out to address both the latency and token tradeoffs. Our strategy was to route the heavy-lifting intermediate summarization steps to a smaller, faster, and less powerful model while keeping the advanced models strictly for the complex synthesis steps.
The idea was that a smaller model would be significantly faster and cost a fraction of the price. The challenge, however, is that smaller models often struggle with complex reasoning out-of-the-box. Our previous prompts were written for advanced models, and simply swapping the model out led to hallucinated citations and lost topical context.
To make this work without a loss in performance, we relied on careful prompt design. By giving the smaller model highly explicit and structured instructions, we successfully solved for:
- Topic relevance: Getting the less powerful model to generate summaries that remained focused on the input query, and correctly using names, dates, and organizational context.
- Citations: Enforcing strict rules to properly carry over source document citations into the summaries, which are important for generating the final output report.
This optimization allowed the smaller model to match the summarization quality of a much more advanced model. We were genuinely surprised by these results. Using a smaller model didn't eliminate the need for significant token usage, but it completely changed the tradeoff math - allowing us to run the heavy-lifting summarization step faster and cheaper, without a noticeable loss in quality.
Conclusion: Synthesis on Demand
Our previous research showed that knowledge graphs can be a very powerful tool for knowledge search. If you have the engineering resources to maintain a graph, we believe you will definitely see gains in your RAG pipeline.
But on the other hand, you don't necessarily have to maintain a pre-computed knowledge graph to understand high-entropy business data. By leveraging on-the-fly compression, dynamic "cliff notes" of a topic are used exactly when a user asks for them - ensuring the context is never stale and is well-aligned with the user's specific intent.
This just-in-time approach to gathering, expanding, and summarizing knowledge bundles essentially creates a localized knowledge graph on demand. While it introduces challenges around query latency and token usage, our research shows that with the right architecture and prompt optimization, frontier-level synthesis can be achieved without the frontier-level price tag. The implication is that decisions around complex topics are backed by the complete, real-time reality of the business.